






Modello di prezzo
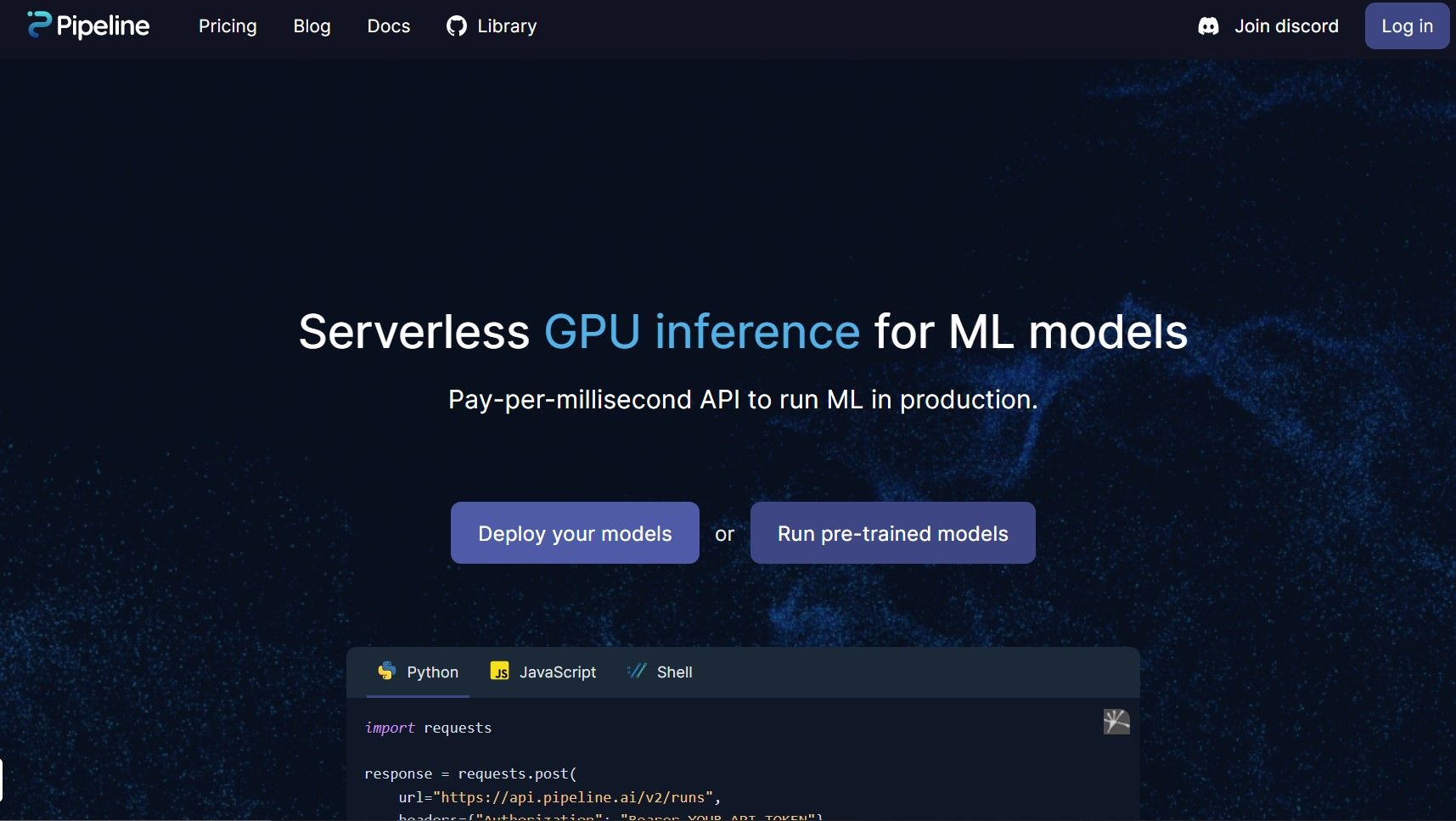
Developer toolsUn nuovo prodotto offre l’inferenza GPU serverless per i modelli ML, eliminando la necessità di gestire i server e fornendo una soluzione economica ed efficiente per le esigenze di elaborazione dei dati.
Descrizione
Vi presentiamo il nostro prodotto innovativo che consente l’inferenza su GPU senza server per i modelli di Machine Learning (ML), portando le vostre capacità di elaborazione dei dati a nuovi livelli! La nostra moderna tecnologia è in grado di aiutarvi a sfruttare la potenza all’avanguardia delle GPU, eliminando la necessità di gestire i server o di preoccuparsi dell’infrastruttura.
Con la nostra piattaforma, è possibile distribuire i modelli di ML in modo semplice ed efficiente, senza dover affrontare problemi di provisioning, manutenzione e scalabilità. Il nostro prodotto è rivolto a coloro che desiderano soluzioni economiche e senza problemi per l’inferenza di Machine Learning.
La nostra API a pagamento al millisecondo consente di eseguire i modelli di ML in produzione, fornendo una soluzione affidabile e scalabile per tutte le esigenze di elaborazione dei dati. Con il nostro prodotto, potete concentrarvi sulla realizzazione di prodotti eccellenti, lasciando a noi la gestione dei server.
Dite addio ai lunghi tempi di attesa, ai costi eccessivi dell’infrastruttura e alle interminabili attività di manutenzione dei server. Il nostro prodotto offre un modo completo, conveniente ed efficiente per sfruttare l’inferenza di Machine Learning su scala. Iniziate subito a utilizzare la nostra soluzione di inferenza su GPU senza server!
Pipeline AI recensioni
Sii il primo a recensire “Pipeline AI”
Pipeline AI alternative
-

ProbeAI è uno strumento basato sull’intelligenza artificiale che semplifica il processo di lavoro con il codice SQL e le tabelle di dati, riduc... leggi di più
-
Shumai è un software open-source ultraveloce, connesso alla rete e compatibile con TypeScript e JavaScript. Offre il massimo delle prestazioni e dell... leggi di più
-

Questo strumento è stato progettato per semplificare il processo di formazione e distribuzione di modelli di apprendimento automatico su AWS SageMake... leggi di più
-
Databorg.ai è una piattaforma che consente di creare bot di risposta alle domande altamente funzionali e precisi, utilizzando dati provenienti da qua... leggi di più
-
Canopy è un software di gestione degli asset alimentato dall’intelligenza artificiale che utilizza l’analisi predittiva per prevenire cos... leggi di più
-
Amazon Bedrock è una piattaforma di AI che aiuta gli utenti a costruire e scalare applicazioni di AI generativa. Offre un’ampia gamma di modell... leggi di più
-
Gamma.AI è una soluzione di prevenzione della perdita di dati basata sul cloud che utilizza il deep learning per fornire una classificazione precisa ... leggi di più
-
Checksum offre agli sviluppatori e ai professionisti della QA un processo di generazione di test semplificato che utilizza sessioni di utenti reali e ... leggi di più
-

È stata lanciata una CLI open source alimentata da GPT-3 per semplificare il flusso di lavoro con una lunghezza di prompt impressionante di circa 840... leggi di più
-
L’API ChatGPT utilizza OpenAI per fornire esperienze di chat senza soglie di registrazione o di pagamento, con utilizzo illimitato e protezione ... leggi di più
-
Polymath è uno strumento di apprendimento automatico che trasforma le librerie musicali in librerie di campioni di produzione analizzando, raggruppan... leggi di più
Non ci sono ancora recensioni.