






Modelo de precios
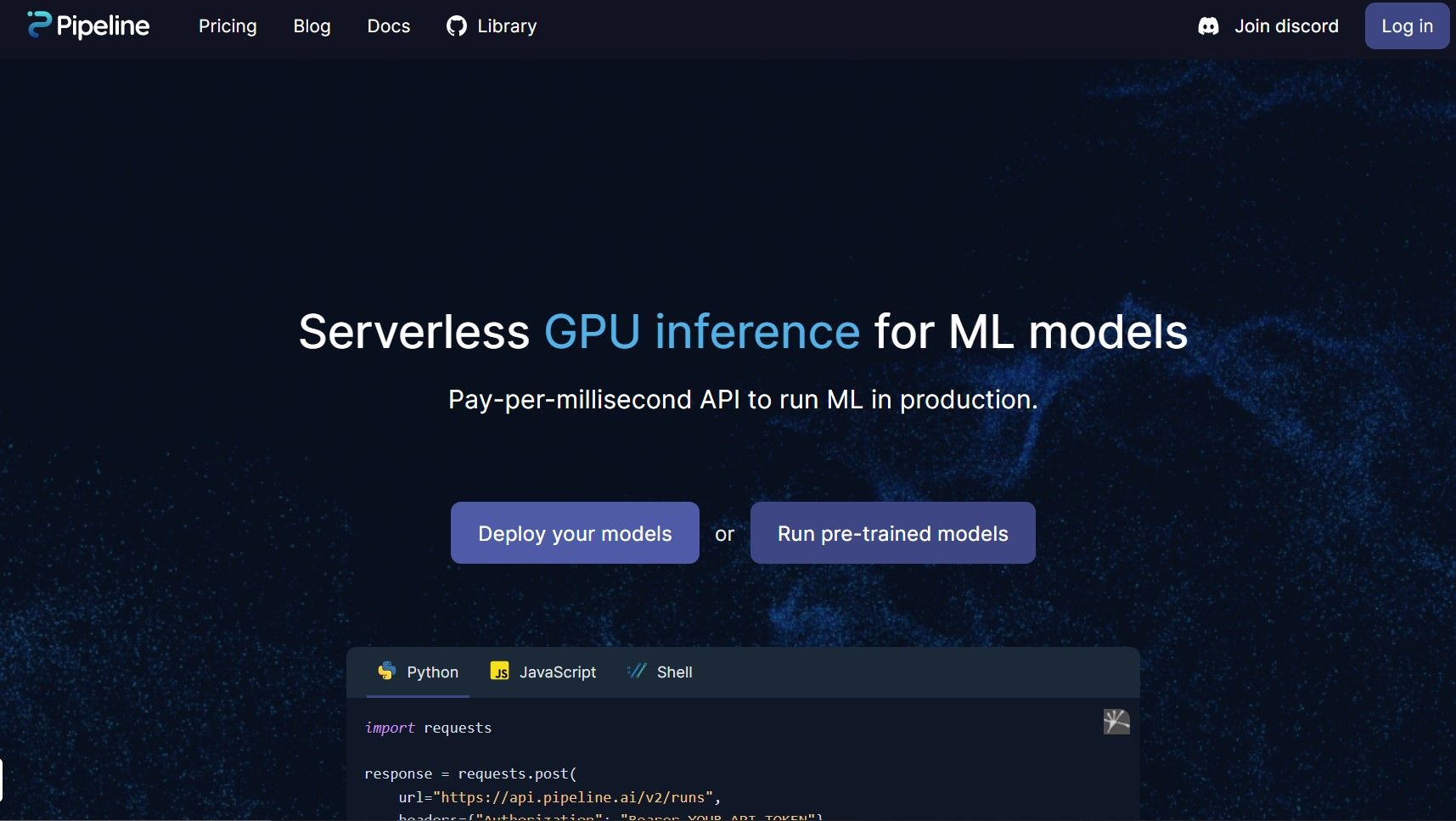
Herramientas para desarrolladoresUn nuevo producto ofrece inferencia GPU sin servidor para modelos ML, eliminando la necesidad de gestionar servidores y proporcionando una solución rentable y eficiente para las necesidades de procesamiento de datos.
Descripción
Presentamos nuestro innovador producto que permite la inferencia en la GPU sin servidor para modelos de aprendizaje automático (ML), lo que eleva la capacidad de procesamiento de datos a nuevas cotas. Nuestra moderna tecnología está aquí para ayudarle a aprovechar la potencia de vanguardia de las GPU, al tiempo que elimina la necesidad de gestionar servidores o preocuparse por la infraestructura.
Con nuestra plataforma, puede implantar sus modelos de ML de forma fácil y eficiente, sin los problemas de aprovisionamiento, mantenimiento y escalabilidad. Nuestro producto está dirigido a quienes buscan soluciones rentables y sin complicaciones para la inferencia del aprendizaje automático.
Nuestra API de pago por milisegundo le permite ejecutar sus modelos de ML en producción, proporcionándole una solución fiable y escalable para todas sus necesidades de procesamiento de datos. Con nuestro producto, puede centrarse en crear productos excelentes y dejarnos la gestión del servidor a nosotros.
Diga adiós a los largos tiempos de espera, a los costes de infraestructura excesivos y a las interminables tareas de mantenimiento del servidor. Nuestro producto ofrece una forma completa, asequible y eficiente de aprovechar la inferencia del aprendizaje automático a escala. Empiece hoy mismo con nuestra solución de inferencia GPU sin servidor.
Pipeline AI reseñas
Se el primero(a) en opinar “Pipeline AI”
Pipeline AI alternativas
-
Databorg.ai es una plataforma que permite la creación de Bots de Respuesta a Preguntas de alto funcionamiento y precisión utilizando datos de cualqu... leer más
-
Amazon Bedrock es una plataforma de IA que ayuda a los usuarios a crear y escalar aplicaciones de IA generativa. Proporciona una amplia gama de modelo... leer más
-
NocodeBooth es una plantilla de aplicación basada en web que permite a los usuarios lanzar fácilmente su propia plataforma de generación de imágen... leer más
-

Moonbeam Exchange es una plataforma de ciencia de datos que permite a los usuarios analizar y tomar decisiones informadas agregando información de m�... leer más
-
Appicons AI es un generador de iconos basado en IA que permite a los usuarios crear iconos profesionales y atractivos con un proceso de 3 pasos y prec... leer más



Aún no hay reseñas.