






Preismodell
Entwickler-ToolsEin neues Produkt bietet serverlose GPU-Inferenz für ML-Modelle, die die Verwaltung von Servern überflüssig macht und eine kostengünstige und effiziente Lösung für Datenverarbeitungsanforderungen darstellt.
Beschreibung
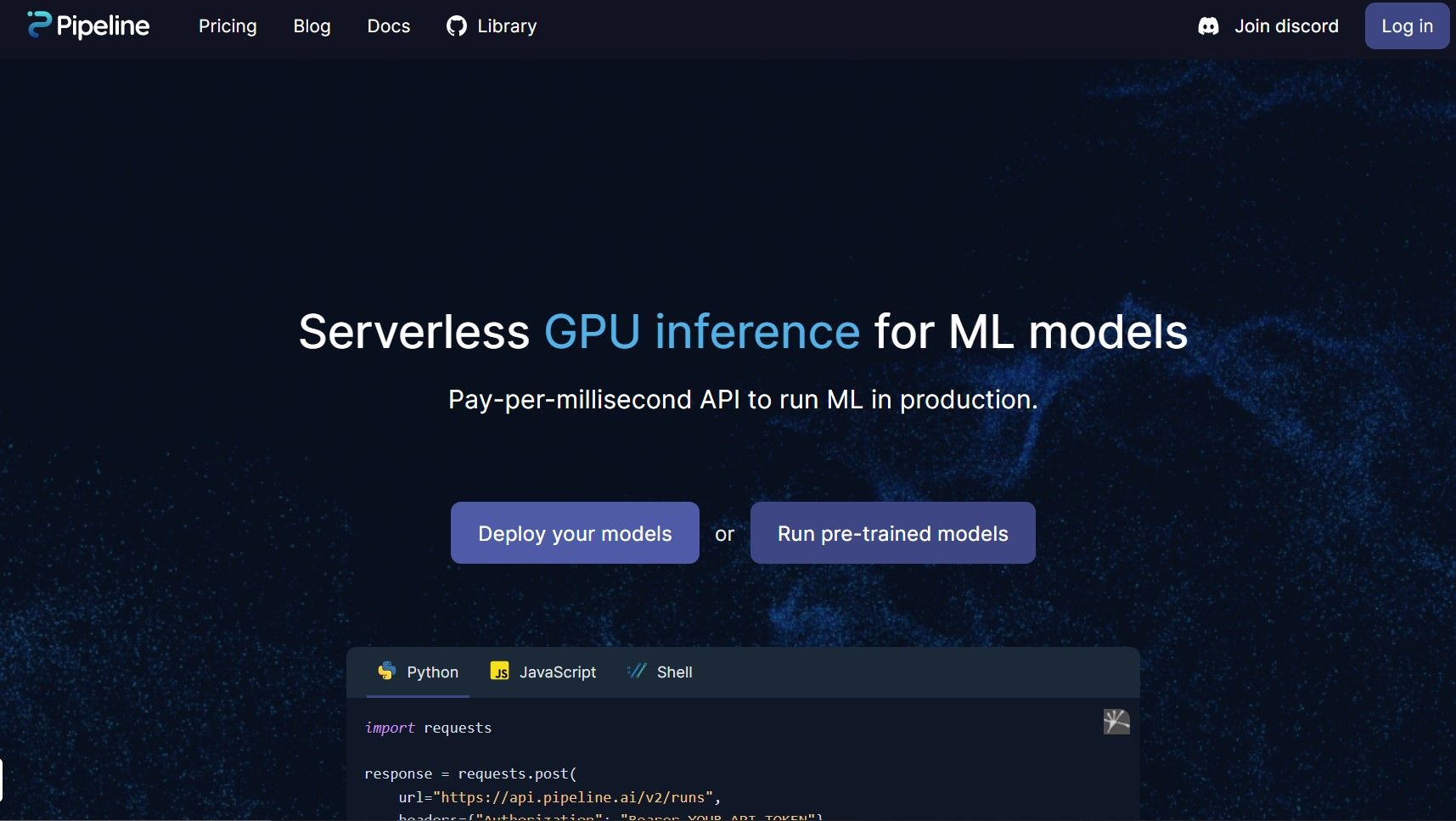
Wir stellen unser bahnbrechendes Produkt vor, das serverlose GPU-Inferenz für Machine Learning (ML)-Modelle ermöglicht und Ihre Datenverarbeitungsfähigkeiten auf ein neues Niveau hebt! Unsere moderne Technologie hilft Ihnen, die Spitzenleistung von GPUs zu nutzen, ohne dass Sie Server verwalten oder sich um die Infrastruktur kümmern müssen.
Mit unserer Plattform können Sie Ihre ML-Modelle einfach und effizient einsetzen, ohne dass Sie sich um die Bereitstellung, Wartung und Skalierbarkeit Gedanken machen müssen. Unser Produkt richtet sich an alle, die unkomplizierte und kosteneffiziente Lösungen für die Inferenz von Machine Learning suchen.
Mit unserer Pay-per-millisecond-API können Sie Ihre ML-Modelle in der Produktion ausführen und erhalten eine zuverlässige und skalierbare Lösung für alle Ihre Datenverarbeitungsanforderungen. Mit unserem Produkt können Sie sich auf die Entwicklung hervorragender Produkte konzentrieren und uns die Serververwaltung überlassen.
Verabschieden Sie sich von langen Wartezeiten, überhöhten Infrastrukturkosten und nicht enden wollenden Serverwartungsaufgaben. Unser Produkt bietet eine umfassende, erschwingliche und effiziente Möglichkeit zur Nutzung von Machine Learning Inferenzen in großem Umfang. Starten Sie noch heute mit unserer serverlosen GPU-Inferenzlösung!
Pipeline AI rezensionen
Schreiben Sie die erste Bewertung “Pipeline AI”
Pipeline AI alternativen
-
Der GPT-4 Security Checklist Generator bietet ein umfassendes und anpassbares Tool für Softwareentwicklungsteams zur Verbesserung der Sicherheit. Er ... weiterlesen
-
Checksum bietet Entwicklern und QA-Experten einen optimierten Testgenerierungsprozess, der echte Benutzersitzungen und maschinelles Lernen für End-to... weiterlesen
-

ProbeAI ist ein KI-gesteuertes Tool, das die Arbeit mit SQL-Code und Datentabellen rationalisiert, Fehler reduziert und die Produktivität von Datenan... weiterlesen
-
Der AI Listing Architect, powered by SmartScout, nutzt KI-Technologie, um Amazon-Produktlistings für SEO zu optimieren, indem er Empfehlungen und Ein... weiterlesen
-
Databorg.ai ist eine Plattform, die dank ihrer fortschrittlichen Datenextraktionstechnologie und Wissensgraphen die Erstellung von hochfunktionalen un... weiterlesen
-
PoplarML ist eine benutzerfreundliche Plattform, die die Bereitstellung von Systemen für maschinelles Lernen vereinfacht und die Bereitstellung produ... weiterlesen
-
Appicons AI ist ein KI-gestützter Icon-Generator, mit dem Benutzer professionelle und attraktive Icons in 3 Schritten und zu flexiblen Preisen erstel... weiterlesen
-
Camel AGI ist ein leistungsstarkes Werkzeug für nahtlose Interaktion, Zusammenarbeit und Problemlösung zwischen KI-Agenten mit rollenbasierter Zusam... weiterlesen
-

Hacker AI ist ein KI-gestütztes Code-Audit-Tool zur Erkennung und Behebung potenzieller Sicherheitsschwachstellen im Quellcode, mit präziser Schwach... weiterlesen
-
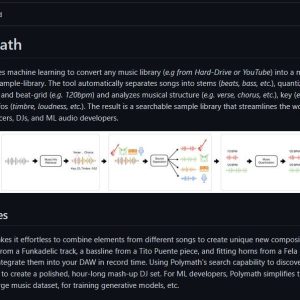
Polymath ist ein Tool für maschinelles Lernen, das Musikbibliotheken in Sample-Bibliotheken für die Produktion verwandelt, indem es Songs analysiert... weiterlesen
-
Amazon Bedrock ist eine KI-Plattform, die Benutzern hilft, generative KI-Anwendungen zu erstellen und zu skalieren. Sie bietet eine breite Palette von... weiterlesen
-
GPU Everything ist eine vielseitige Lösung für die Ausführung von Anwendungen in einer Docker-Umgebung mit Autoscale Inference, mit der Unternehmen... weiterlesen
Es liegen noch keine Bewertungen vor.